The Official Scroll Blog
A Tutorial
This tutorial will walk you through how to use Scroll for data analysis and visualization, from basic concepts to advanced techniques.
What makes Scroll great for data science?
Scroll combines the simplicity of markdown-style syntax with powerful data transformation and visualization capabilities. You can:
- Load data from various sources (CSV, JSON, etc.)
- Transform and analyze data with simple commands
- Create beautiful visualizations
- Publish instantly using ScrollHub
- All in a simple, readable format
Let's dive in!
Part 1: Getting Started with Data
Loading Sample Datasets
Scroll comes with several sample datasets. Let's start with the famous iris dataset:
iris
printTable
| sepal_length | sepal_width | petal_length | petal_width | species |
|---|---|---|---|---|
| 6.1 | 3 | 4.9 | 1.8 | virginica |
| 5.6 | 2.7 | 4.2 | 1.3 | versicolor |
| 5.6 | 2.8 | 4.9 | 2 | virginica |
| 6.2 | 2.8 | 4.8 | 1.8 | virginica |
| 7.7 | 3.8 | 6.7 | 2.2 | virginica |
| 5.3 | 3.7 | 1.5 | 0.2 | setosa |
| 6.2 | 3.4 | 5.4 | 2.3 | virginica |
| 4.9 | 2.5 | 4.5 | 1.7 | virginica |
| 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 5 | 3.4 | 1.5 | 0.2 | setosa |
You can also load datasets from Vega's collection:
sampleData zipcodes.csv
limit 0 5
printTable
| zip_code | latitude | longitude | city | state | county |
|---|---|---|---|---|---|
| 501 | 40.922326 | -72.637078 | Holtsville | NY | Suffolk |
| 544 | 40.922326 | -72.637078 | Holtsville | NY | Suffolk |
| 601 | 18.165273 | -66.722583 | Adjuntas | PR | Adjuntas |
| 602 | 18.393103 | -67.180953 | Aguada | PR | Aguada |
| 603 | 18.455913 | -67.14578 | Aguadilla | PR | Aguadilla |
Basic Data Operations
Let's explore some basic operations on the iris dataset:
iris
summarize
printTable
| name | type | incompleteCount | uniqueCount | count | sum | median | mean | min | max | mode |
|---|---|---|---|---|---|---|---|---|---|---|
| sepal_length | number | 0 | 8 | 10 | 57.699999999999996 | 5.6 | 5.77 | 4.9 | 7.7 | 5.6 |
| sepal_width | number | 0 | 8 | 10 | 31.599999999999998 | 3.2 | 3.1599999999999997 | 2.5 | 3.8 | 2.8 |
| petal_length | number | 0 | 8 | 10 | 39.8 | 4.65 | 3.9799999999999995 | 1.4 | 6.7 | 4.9 |
| petal_width | number | 0 | 7 | 10 | 13.699999999999996 | 1.75 | 1.3699999999999997 | 0.2 | 2.3 | 0.2 |
| species | string | 0 | 3 | 10 | virginica |
This gives us summary statistics for each column.
Let's look at filtering:
iris
where species = setosa
printTable
| sepal_length | sepal_width | petal_length | petal_width | species |
|---|---|---|---|---|
| 5.3 | 3.7 | 1.5 | 0.2 | setosa |
| 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 5 | 3.4 | 1.5 | 0.2 | setosa |
Part 2: Data Visualization
Basic Plots
Let's start with a simple scatterplot of the iris data:
iris
scatterplot
x sepal_width
y sepal_length
title Sepal Length vs Width
fill species
Line Charts
Let's look at some time series data:
sampleData seattle-weather.csv
parseDate date
linechart
x date
y temp_max
title Maximum Temperature in Seattle
stroke steelblue
Bar Charts
Let's create a bar chart showing precipitation:
sampleData seattle-weather.csv
groupBy weather
reduce precipitation mean precip_avg
barchart
x weather
y precip_avg
fill teal
title Average Precipitation by Weather Type
Part 3: Advanced Data Transformations
Grouping and Aggregation
Let's look at some more complex transformations:
sampleData weather.csv
groupBy weather
reduce temp_max mean avg_max_temp
reduce temp_min mean avg_min_temp
orderBy -avg_max_temp
printTable
| count | weather | avg_max_temp | avg_min_temp |
|---|---|---|---|
| 129 | drizzle | 18.555813953488368 | 10.143410852713178 |
| 459 | rain | 15.535294117647041 | 9.04727668845315 |
| 1674 | sun | 18.064157706093184 | 8.87275985663083 |
| 78 | snow | 4.528205128205127 | -1.4346153846153844 |
| 582 | fog | 15.261855670103111 | 8.527319587628869 |
Creating New Columns
Let's add some computed columns:
iris
compute ratio {sepal_length}/{sepal_width}
where ratio > 2
printTable
| sepal_length | sepal_width | petal_length | petal_width | species | ratio |
|---|---|---|---|---|---|
| 6.1 | 3 | 4.9 | 1.8 | virginica | 2.033333333333333 |
| 5.6 | 2.7 | 4.2 | 1.3 | versicolor | 2.074074074074074 |
| 6.2 | 2.8 | 4.8 | 1.8 | virginica | 2.2142857142857144 |
| 7.7 | 3.8 | 6.7 | 2.2 | virginica | 2.0263157894736845 |
Part 4: Advanced Visualizations
Heatmaps
Let's create a heatmap of annual precipitation values:
sampleData seattle-weather.csv
splitYear
groupBy year
reduce precipitation mean precipitation_mean
select year precipitation_mean
transpose
heatrix
Multiple Views
You can create multiple visualizations:
iris
scatterplot
x sepal_length
y sepal_width
fill species
barchart
x species
y sepal_length
fill teal
title Sepal Length by Species
Conclusion
This tutorial covered the basics of data science with Scroll. Some key takeaways:
- Scroll makes it easy to load and manipulate data
- Visualizations are simple to create and customize
- Complex transformations can be done with simple commands
- Everything is readable and version-controllable
What is Scroll?
Scroll is a language for those who believe that what they cannot build with as few pieces as possible they do not understand.
What is Scroll?
Scroll is a symbolic language.
What is a symbolic language.
A language you write with symbols.
What is a symbol?
A symbol is a mark repeated to correlate to a pattern in nature.
What is a mark?
A mark is a discoloration of a surface.
What is a symbolic language?
A symbolic language is a collection of symbols and symbol sequences that can be used to trigger the same electrical phenomena in the brain of an observer that seeing that pattern occur in nature would trigger.
How do I use a symbolic language?
By writing documents.
What is a document?
It is a collection of marks on a surface.
What is Particle Syntax?
It is the syntax that Scroll uses.
What is a syntax?
It is a set of rules for how to break up a document into symbols.
What is a digital document?
It is a file.
What is a file?
It is a digital representation of a document as a series of bits.
What is a bit?
A bit is a persistent location in space that has 2 states: a 1 or 0; a true or false; an on or off; a black or white; a hot or cold; a high or low.
What is a character?
A character is a 2D mark that maps to a unique fixed length bit sequence.
What is a character encoding?
A map of bit sequences to characters.
What character encoding does Scroll use?
UTF8. For now.
What is a word?
A word is a list of characters delimited by a word delimiter sequence.
What is an atom?
An atom is another word for word in the Scroll language.
What is a line?
A line is a sequence of atoms in the Scroll language delimited by a newline sequence.
What is a Particle?
A particle in Scroll refers to an object that contains both atoms and a collection of particles referred to as the particle's subparticles.
Are all particles also subparticles of a higher particle?
Yes.
What is a Parser?
A Parser is a particle that consumes certain other particles to perform transformations.
What transformations can a Parser perform?
A Parser can perform a variety of transformations but the most common are to:
- compile one particle in one language to another language.
- format a particle into a standardized format
- check a particle for errors
- evalute the instructions in a particle and return the results
- execute commands contained in the particle
What is the syntax of Scroll?
The syntax of Scrolls is Particle Syntax, or just Particles for short.
What does Particle Syntax do?
Partilces tells you how to divide a binary sequence into parts.
What are the components of Particle Syntax?
- A sequence of binary bits is converted into characters using UTF8
- Atoms are sequences of characters separated by a single space.
- Particles are a sequence of atoms separated by a newline.
- Subparticles are indicated by a single indented space.
How do I make a subparticle?
- Just indent a particle by 1 space more than its parent particle.
- For example, because I started this line with one space more than the line above, this line is a subparticle of that line.
- And then this line, starting with 2 spaces, is a subparticle of the line above it.
- But this line is a subparticle of the line above that starts with "Just"
- For example, because I started this line with one space more than the line above, this line is a subparticle of that line.
Can I use the Particles, Parsers, and Scroll concepts to design 2D or 3D languages that don't use computers at all?
Yes. But generally when we talk about PPS we are talking about the form designed for binary and computers.
What is Parsers?
Parsers is a symbolic language where one defines Particles that can consume other Particles. It is a language for making other languages.
What is Scroll?
Scroll is a language made out of Parsers.
What is the purpose of the Parsers language?
The purpose of the Parsers Language is to make Scroll.
What is the purpose of Scroll?
The purpose of Scroll is to help humans communicate with humans and machines.
How does one use Scroll to communicate?
By writing Scroll documents (aka Scroll Programs) to create things.
What kinds of things is Scroll currently best at creating?
Knowledge bases, blogs, websites, web pages, charts, animations, data science reports, ebooks, web forms, maps, that sort of thing.
Why use Scroll and not just write HTML directly?
Scroll helps you better understand what you are writing about and anything HTML can make Scroll can make in fewer symbols.
Scroll is a language for those who believe that what they cannot build with as few pieces as possible they do not understand.
What is ScrollHub?
ScrollHub is a super server for creating and publishing websites instantly using Scroll.
What is a cue?
Cue refers to the first atom in a particle.
What is the significance of the cue?
When communicating you want to communicate the most important information first, so the cue is often the most important information.
What is the cue used for?
Most parsers use the cue to determine whether they should consume a particle or not.
Can parsers use other ways to match against particles?
Yes.
What's another commmon way for parsers to match particles?
Regular expressions.
Can I build Scroll using only Particles and Parsers and no other languages?
Currently no.
Parsers does not have enough functionality yet to be able to write parsers that provide everything Scroll needs.
What other language do I currently need?
The primary implementation of Parsers currently is half Parsers, half Javascript.
How does Parsers parse Scroll?
The Parsers program is parsed and compiled by a Javascript implementation of Parsers which generates a Parser and compiler for Scroll programs.
Do I need to master Javascript to use Parsers?
If you've mastered Javascript then using Parsers should be easy once you get the hang of it.
Does Parsers have inheritance?
Yes.
Does Particle Syntax have types?
No.
Does Parsers have types?
Yes. Parsers has atom types.
Is Scroll like Lisp?
Scroll and Parsers implement many of the best ideas from Lisp, and leave out a lot of unnecessary things (like the parens).
Is Scroll designed for humans or AIs?
Both.
October 1, 2024 — If you want to make web forms the inefficient way, there are many other places to read how to do that.
If you want to learn how geniuses are doing web forms, read on.
One Field at a Time is Retarded
Building forms for one-field-at-a-time data entry is inefficient.
People can't copy/paste your forms. E-receipts are a pain. Auto-form fill works poorly.
It's a huge waste of your users' time that retards them and your business.
And it will always be this way.
Entire Form in One Field is Genius
Everything becomes radically simpler. People can do things like copy/paste entire applications; email them; version control them; collaborate on them; all effortlessly.
And guess what? You can still also compile to a one-field-at-a-time HTML form and allow users to swap back and forth! It's pure win, no loss.
You can use this TODAY!
This now ships in Scroll. Here is a test form. You can also see it in use in many of our products.
Because this is new technology, it is not for those that need spoon feeding. Believe it or not, making web forms also used to be complicated.
(If you need this urgently, don't have time to figure it out yourself, and need to hire professional consulting, feel free to get in touch.)
Don't whine. Build.
I'm tired of reading all the whiners commenting about how our CSS doesn't look so pretty yet, or the tiny little feature you need that isn't supported.
I don't care much to hear from whining losers.
I want to hear from winners. From builders. From those who strive for genius.
Beautiful designs, autoincrement, auto timestamp, joins, decision trees, all that stuff is coming. The world is gonna love this.
If you are a winner, a builder, a genius, join us on GitHub or Reddit.
September 2, 2024 — Today on HackerNews Kevin Damm had a great idea: put a <link> tag on blogs to point to the git Source Code Repository, much as blogs today have <link> tags pointing to their RSS feeds.
I've added this feature to Scroll and it's live now. If you View Source of this page, you'll see:
<link rel="source" type="application/git" title="Source Code Repository" href="https://github.com/breck7/scroll">
<link rel="alternate" type="application/rss+xml" title="The Official Scroll Blog" href="feed.xml">
Client applications can start looking for and taking advantage of these tags.
RSS was great, but it's no match for Git Clone
Git clone solves a million problems.
You get a copy of the entire works of your favorite authors that is blazing fast, works offline, is searchable, transformable, censorship resistant, auditable, more trustworthy, ad free, tracker free, et cetera.
There is no comparison to the old ways of doing things.
What do you think?
Have you already been doing this? Are there ways we can make it better? Would love to hear your feedback!
Notes
vladimyr on bluesky dug up a couple of cool examples of prior art.
Particles, Scroll, and the Parsers Programming Language
I've recorded a short video (1 minute version; 10 minute version) about our recent work which has begun to eat the software world.
Outline
1. Is this stuff relevant to you?
Whether you are an experienced, aspiring, or casual programmer, yes.
If you are a writer, yes.
If you are a thinker, yes.
If you are a builder, yes.
If you choose to always remain illiterate to keep your brain different than the crowd, then no. (I applaud your brave creative choice and as a scientist I'm curious to see what happens!)
2. What is Particle Syntax (Particles)?
One liner: a syntax-free syntax for splitting files into particles (separated by line breaks) which can have atoms (separated by spaces) and subparticles (indented lines).
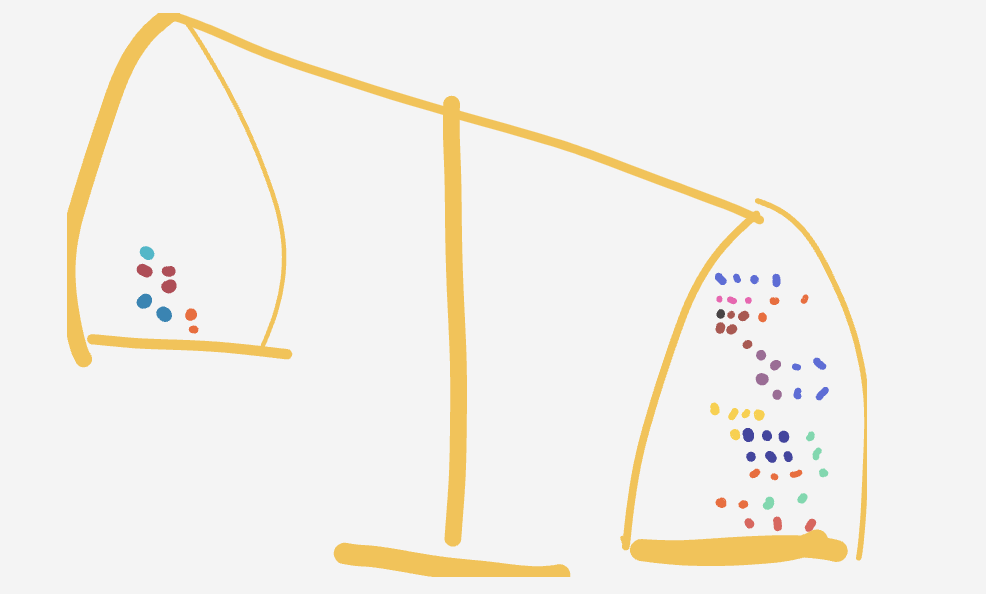
Each line is a particle. Each dot is a atom. Particles lets you easily compare programs and see which one is simpler (less heavy!).
3. What is Scroll?
One liner: Scroll is a language for scientists of all ages where you write and combine particles (written in Particles) to evolve and publish your most intelligence ideas to HTML, PDFs, CSVs, JSON files, movie files, audio files, slideshows, charts, books, et cetera.
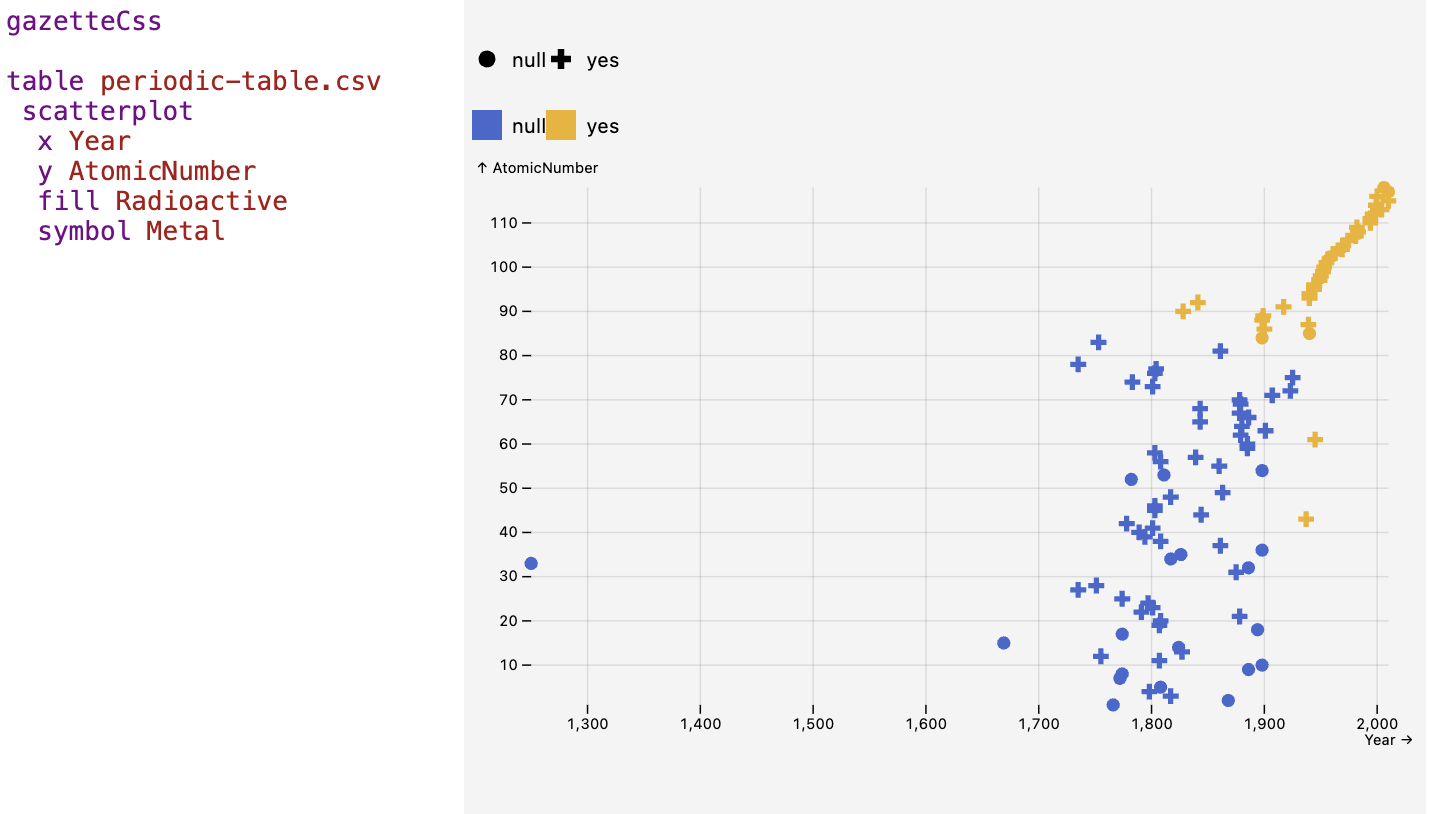
Scroll is a collection of Parsers that allow you to evolve and publish your most intelligent ideas.
4. What is Parsers?
One liner: Parsers is a programming language where programmers write parsers (written in Particles) which consume particles (written in Particles) and also contain logic for translating those particles into actions on computing machines.

Programmers who understand how computing machines work write Parsers to translate particles into executable machine code.
5. How do you get started?
August 9, 2024 — Tables, aka spreadsheets, are arguably the most important visual thought tool.
But no one has designed the perfect textual language for manipulating them.
Until now.
Say hello to Tables
Acknowledgements
Tables evolved over the past decade primarily by:
- just doing what Hadley Wickham did in dplyr
- using Mike Bostock's d3 under the hood
- reading all of Jeffrey Heer's papers
- thinking about what would be the best tool for Max Roser and Hannah Ritchie.
August 2, 2024 — I like collections of interesting numbers, such as BioNumbers. Animated counters provide a useful perspective when pondering large numbers. I wanted to make it as easy as possible for anyone to create these counters.
So, today I added a new parser to Scroll: counter.
counter 1.1 Heartbeats
Since you loaded this page...
July 28, 2024 — Do you love those GitHub Activity Charts and want to make your own but don't know what they are called or what library to use and your work is busy and you have kids and sorry I'll call you back someone is crying?
Introducing Scroll's newest parser: heatrix!
heatrix let's you craft custom heatmap visualizations with the fewest keystrokes possible.
Heat Map + Matrix = Heatrix
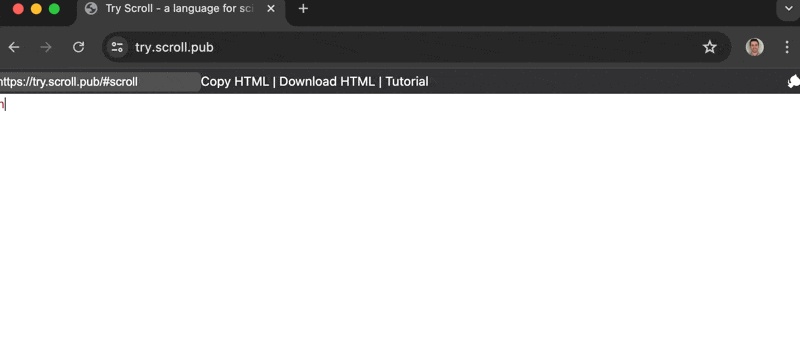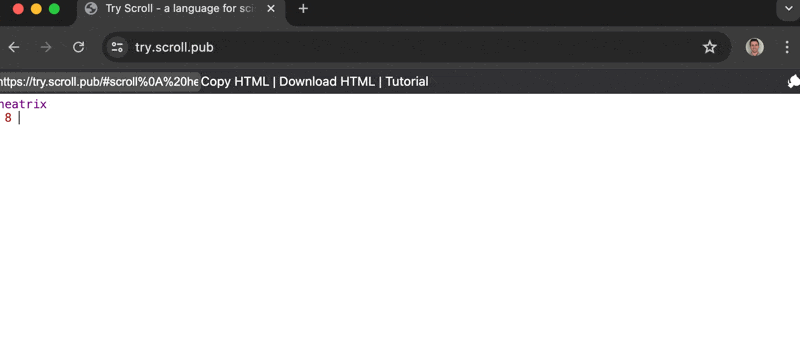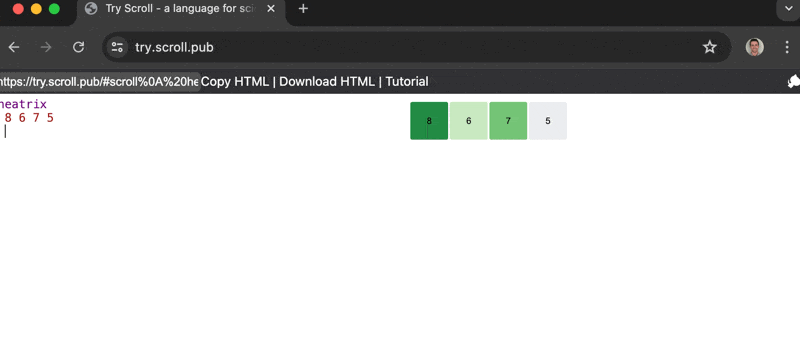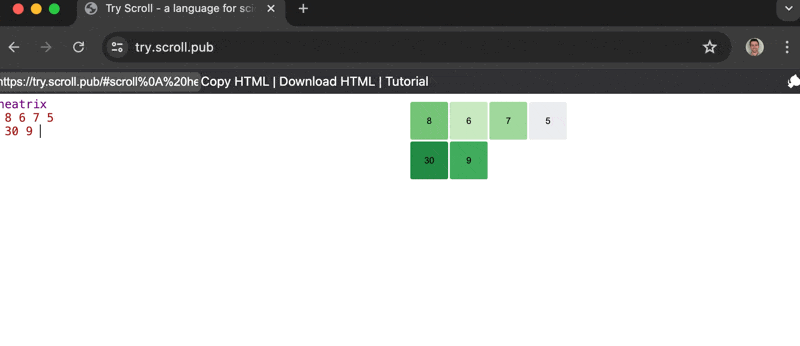
Source code. Gif made with CleanShotX.
Not just a library, it's a microlanguage!
heatrix is a microlang that let's you customize your visualizations using "directives":
Adjust the height/width of individual cells, columns, or rows:
heatrix
h20;Scroll h20;PLDB
400 700
Use your own custom color palettes and set your own thresholds:
heatrixAdvanced
table
h10;w30 '2015 '2016 '2017 '2018 '2019 '2020 '2021 '2022 '2023 '2024
h30;w30; 0 0 5 1 2 11 15 10 12 56
scale
#ffebee 0
#ffcdd2 1
#ef9a9a 5
#e57373 10
#ef5350 25
#b71c1c 50
Like Heatrix? There's more where that came from!
Join the World Wide Scroll Beta today!
If you like heatrix and want to see more stuff like this, but a folder on the World Wide Scroll beta and good things will come your way:
July 16, 2024 — Imagine a single plain text file named contacts.scroll where you stored the contact info for your family, friends, and colleagues, and you could track changes with git, compile it to a beautiful PDF or HTML page with search and sort, and it would also compile to CSV and/or JSON for import into iPhone, Android, Gmail, Outlook, et cetera?
Also imagine that this tool is free, open source, and public domain.
Introducing Contacts, a microlanguage (currently 23 lines of code, including comments) that makes it as concise as possible to add, prune, display, print and export your contacts.
There's almost nothing to learn (the code is self-explanatory).
In fact, it's almost guaranteed that using Contacts you will need to write less (we've taken every unnecessary character out).
Example
👤 Jack Doe
phone +1 (555) 123-4567
email john.doe@example.com
birthday 2/23/84
notes Daughter - Samantha.
👤 Jill Smith
phone +1 (555) 123-4562
email jill@gmail.com
birthday 1/23/80
How to use
- Create a file named something like
contacts.scrollwith this content:
// You can import the file, or just copy/paste the 21 lines of code here.
[pathToScroll]/microlangs/contacts.parser
title My Contacts
buildConcepts contacts.csv contacts.json contacts.tsv
buildHtml
theme gazette
mediumColumns 1
printTitle
table
printTable
tableSearch
👤 Jack Doe
phone +1 (555) 123-4567
email john.doe@example.com
birthday 2/23/84
notes Daughter - Samantha.
👤 Jill Smith
phone +1 (555) 123-4562
email jill@gmail.com
birthday 1/23/80
- Run
scroll build
Done! You should now see a contacts.html file for display and printing as well as TSV, CSV, and JSON files.

Contacts is interoperable with pen and paper.
What do you think? Anything that should be added/removed/improved?
Notes
- The idea for Contacts was sparked by this tweet from Tyler Tringas.
Woohoo!
Your blog is on top of Reddit!
OH NO.
There's a typo in your url. 🤦
What do you do?
You try to calm yourself down.
Almost no one looks at the url and the content of the article is what's important and the traffic is coming
But then you think all I can see is that i before e after c!
But then you think is that really a rule and maybe that's how it's spelled in London?
You can't help yourself.
It's an affront to your craftsmanship to not correct the bad filename.
You know you can so easily rename the file but then existing links will break and so you'll have to add redirects but that means more files to maintain or god forbid that would require adding a server and you just love your static blog and it's almost 2pm and you have to leave and pick up the kids from school what do you do!?!!
Or do you just break the links and going forward everyone will have the proper URL but everyone who clicks the old links will see an unhelpful 404 and you reflect on how great this thing that Tim Berners-Lee gave to the world is and how could you litter his creation with unhelpful 404s?
If the story above resonates with you, the bad news is you may suffer from Broken Link Phobia. Luckily, there is now a cure.
Introducing: Helpful 404's - never worry about broken links again!
Scroll now comes with a way to generate a very helpful 404 page so your visitors will get redirected to the right place even if the URL they clicked is off by a few characters.
The best part? It works entirely client side on static sites.
How to use
Step 1 Create a sitemap:
buildTxt sitemap.txt
baseUrl https://scroll.pub/
printSiteMapStep 2 Create a 404 page:
buildHtml
Sorry, the url you requested was not found.
helpfulNotFound sitemap.txtThat's it! The helpfulNotFound parser in Scroll will add Javascript to the 404 page that fetches all the urls found in the sitemap and shows the user the closest match. As a bonus, you also get a sitemap.txt file great for Google SEO and other uses.
See it in action here by clicking on this intentionally broken link:
I've been using Helpful 404s on all my sites for the past couple of months and it's been delightful.
I no longer spend any time worrying about making improvements to URLS.
I just do it and I know that users following old links will still have a good experience.
If you like stuff like Helpful 404's, there's a lot more like that in Scroll, which is public domain and open source.
Try it today, and if you like what we are doing please consider bringing your site to the World Wide Scroll!
ScrollSets are very useful once you get going. But starting from scratch could be a bit tedious.
Not anymore!
Just drop your CSV or TSV into the textarea below to generate a ScrollSet.
(P.S. using LLMs with ScrollSets is another great way to get started)
Your Data:
ScrollSet:

July 1, 2024 — Regardless of what languages you write your programs in, you probably maintain files like changeLog.txt or releaseNotes.txt.
Change logs are very helpful for:
- informing your users of new features and bug fixes
- providing detailed technical information to your development team (and open source contributors)
- periodical data analysis for strategic project planning - how fast are we shipping new features? fixing bugs? breaking things?
What if there was 1 language that let you do all 3 things at once?
Introducing Changes, a microlang (only 70 lines of code, including comments) that makes it as concise as possible to write, read and analyze change logs.
Changes generates a pretty HTML file for your end users; allows for including unlimited detailed technical information for your developers; and generates summary statistics as TSV, CSV, and JSON for your project managers.
There's almost nothing to learn (the code is self explanatory).
In fact, it's almost guaranteed that using Changes you will need to write less (we've taken every unnecessary character out).
Example
We use Changes for the Scroll Release Notes.
Be sure to check out the source code that generates that HTML.
How to use
- Install Scroll
npm install -g scroll-cli
- Create a release notes file:
title My Release Notes
printTitle
buildConcepts releaseNotes.csv releaseNotes.json releaseNotes.tsv
// You can import the changes parsers or just copy/paste the 70 lines into your own file.
[pathToScroll]/microlangs/changes.parser
thinColumns
📦 0.1.1 7/1/2024
🏥 fixed bug in command line app
📦 0.1.0 7/1/2024
🎉 added command line app
endColumns- Run
scroll build
Done! You should now see a releaseNotes.html file as well as a TSV, CSV, and JSON file.
What do you think? Anything that should be added/removed/improved?
Related
June 24, 2024 — I engineered on many innovative data science tools, including Grapher and Ohayo[1].
So I was excited to see Observable launch something new: Plot.
Plot is already great on its own. It handles many of the hard parts of data vis, and it's open source, so we can help them fix the parts that are still a little rough.
But I found a way to take Plot to the next level: I combined it with Scroll.
The Plot/Scroll integration is early, but I can already tell it will evolve into a very useful data science tool.
A Scatterplot with 2 words
You can now make scatterplots with 2 words.
Obviously you want to add a few more words, but I don't think I'm exaggerating when I say that this is the simplest way to generate a scatterplot now and forever will be (until the day when we have mind-reading machines that can generate a scatterplot with zero words).
But enough talk, let's see some code. A tutorial is below.
To follow along, create a new website in 1 second using ScrollHub or install Scroll locally with npm install -g scroll-cli.
Step 1: Generate a scatterplot with 2 words
planets.csv
scatterplot
Step 2: Add a title
planets.csv
scatterplot
title The Planets
Step 3: Add inline data
table
scatterplot
title The Simpson Family
x age
y height
label name
data
name age height
Homer 39 183
Bart 10 137
Lisa 8 120
Step 4: Everything everywhere all at once
planets.csv
scatterplot
title The Planets in our Solar System
subtitle Note: This chart is not designed to be pretty but to show all the current features in the Scroll/Plot integration.
caption Data from Wikipedia.
x yearsToOrbitSun
y moons
fill diameter
radius diameter
label id
symbol hasLife
That's it (for now)!
If you like where this is headed, give us a star on GitHub.
[1] The difference between programming and engineering? It takes programming to make a program that works. It takes engineering to make a program that barely works.
June 23, 2024 — Regardless if you specialize in React, Rails, Django, Next, Java, C#, or ObjectiveC, you probably use templates to start new projects.
Templates generate a handful of files like readme.md, .gitignore, and main.
They also initialize a handful of directories like src/ and tests/.
What if it was even easier to make, edit and use these templates?
Introducing Stamp, a microlang (only 60 lines of code, including comments) that makes it as concise as possible to write, edit, share and expand project templates.
How to use
- Install Scroll
npm install -g scroll-cli
- Create
myFirstStamp.scroll
stamp
.gitignore
*.html
readme.scroll
# My First Stamp
<script src="scripts/hello.js"></script>
scripts/
hello.js
console.log("Hello world")
- Run
scroll build
Done!
Stamp was jointly created by me and Guillaume Papin. Other tools (listed below) do similar things, but with some slight differences.

Prior Art
by Breck Yunits
April 29, 2024 — Scroll is a new language for building HTML and CSV files that powers blogs, websites and knowledge bases.
I often need plain text outputs in addition to HTML files.
I used to make those plain text versions copying and pasting text by hand.
Now Scroll has plain text output built-in.
How do I tell Scroll to build plain text files?
Add a single line: buildTxt
buildTxt
Hello world.scroll build will create example.txt. Done!
You may want to put buildTxt into header.scroll or footer.scroll to build text files for many pages at once.
I've loved this new feature in Scroll.
Plain text is a timeless way to read, review, and share your thoughts!
Hope you enjoy it as much as I have!

More examples of ScrollSets from sets.scroll.pub.
April 21, 2024 — The source code for this blog post contains a ScrollSet about the planets and generates this HTML file as well as a CSV, a TSV, and a JSON file. This page demonstrates ScrollSets.
ScrollSets are useful for small single day projects and large multi-year projects with thousands of concepts like PLDB (a Programming Language Database).
ScrollSets are normal plain text files written in Scroll that also contain measurements of concepts and output that data into formats ready for data visualization and analysis tools.
ScrollSets are line oriented but represent a table(s). You might call them deconstructed csvs or deconstructed spreadsheets.
- Use LLMs to instantly generate ScrollSets that are ready for human verification and improvement.
- Intermingle structured data with markup to annotate any and every part of a ScrollSets while still generating strict tabular files for data analysis tools.
- Put data, schema, citations, and documentation all in one (or more) plain text file(s) to easily share, collaborate on, and improve, all tracked by git for trust.
- Add unlimited citations (or none) to every measurement.
Quick Code Example:
This ScrollSets has 2 measures (columns) and 2 concepts (rows).
Documentation, column definitions, rows and *any notes/markup/content* can go in the same file.
# Measures (aka Header, aka Columns, aka Schema)
idParser
// Every concept needs an "id" (or other concept delimiter)
extends abstractIdParser
moonsParser
extends abstractIntegerParser
# Concepts (aka Rows)
id mars
moons 2
// I verified moon count with Google. - BY
id jupiter
moons 63
// Note: the moons of Jupiter have their own Wikipedia Page
https://en.wikipedia.org/wiki/Moons_of_Jupiter moons of Jupiter
buildConcepts demo.csv
The code above generates an HTML page and this:
id,moons
mars,2
jupiter,63Overview:
- ScrollSets are built from 4 atomic elements:
- concepts
- think of rows in a spreadsheet
- denoted by a line starting with
id - concepts are multiple lines of measurements
- measures
- think of these as the column names in a spreadsheet, along with meta information about the column
- aka "parsers"
- measures are defined in Parsers that start with a line like
moonsParser
- values
- these are just the values of the measurements
- measurements
- concept & measure & value = measurement
- 1 measurement = 1 line
- measurements can have nested comments that are stripped when compiling to TSV/CSV
- concepts
How to use
- A concept is like a row in a database. All concepts need an id (or other concept delimiter). When you write
id [conceptId], Scroll knows that is the beginning of a new concept. - Measure definitions (aka "parsers") must come before the first concept and are written as Parsers, just like any other Scroll Parser. Measure parsers need to extend one of the abstract measure parser classes defined in
measures.scroll. - Measurements are then done like this
appeared 2024
FAQ
Isn't the better idea to enhance existing spreadsheet GUIs with LLM generation capabilities?
Almost certainly. Using ScrollSets will be much slower and worse than future spreadsheet apps with carefully crafted LLM integrations.
However, it's important to also have simple, lower tech, timeless tools and ScrollSets is one of those.
Can't you do this same thing with YAML and/or Markdown?
Yes! You can easily achieve the same thing as LLMs & ScrollSets using LLMs & YAML, or LLMs & YAML & Markdown.
For YAML, just put your documentation and schema in YAML comments up top and then have a tiny script to read that YAML and dump CSV/TSV/JSON or whatever. YAML gives you loads of data structures to use and is widely supported in many languages. But generating HTML from the same file would require more work.
If you want to intermix markup content with your data, you can use Markdown to add the marked up content and then have code sections embedding the YAML and a tiny script to parse out those YAML blocks and write your data to disk.
So, why use Scroll for storing data instead of YAML?
Either can do the job. I expect the Scroll design to end up being more ergonomic, but that might not be true or may be unimportant.
If you don't like Scroll's (evolving) version and want to switch it will always be straightforward to automatically refactor to YAML.
What other related work is out there?
This is a simple pattern to implement, so I'm sure it is likely it has been done a few times before. Please let me know so I can include links to--and learn from--any other prior art.
What are the advanced features?
- Types correctly exported in JSON
- Supports nested measures
- Support for computed measures
- Autojoins across files on ids+
- Auto generates normalized tables for array measures+
- Support for text blobs+
+ Planned.
What is the origin of ScrollSets?
LLM dataset generation is a major breakthrough in datasets. ScrollSets are, at best, a minor improvement. They are designed to work alongside LLMs to help solve the Dataset Needed problem.
ScrollSets evolved out of TrueBase. ScrollSets have eliminated the need for the TrueBase software (and existing TrueBase sites should be migrated to ScrollSets), but were informed by the TrueBase build experience.
Although ScrollSets are designed for a world with LLMs, the design is meant to be useful without them as well, and would also have been mildly useful 30 years ago.
What were the design goals?
- Have an LLM do the bulk of the work while humans supervise to remove hallucinations.
- Can store everything (documentation, schema, all concepts) in 1 clean plain text file or split into many files (using the
importparser). - The ScrollSet syntax balances looseness useful in creative thinking with the tightness needed by tabular data visualization and analysis tools.
Why are measures and concepts root-level features and not indented?
The normal way to implement this in Scroll would be something like:
measures
id string
moons int
concept
id mars
moons 2
concept
id jupiter
moons 63
The flat design was chosen for ergonomic reasons. ScrollSets seem like they might be useful enough to be worth breaking from Scroll convention a bit. Like all things in Scroll, ScrollSets are an experiment, and maybe this design will evolve.
Extended Example: a Planets ScrollSet
Below is the ScrollSet embedded in this Scroll file.
Measurements of the measures
Extended Measures Example
idParser
extends abstractIdParser
diameterParser
extends abstractIntegerMeasureParser
description What is the diameter of the planet?
surfaceGravityParser
extends abstractIntegerMeasureParser
description What is the surface gravity of the planet?
yearsToOrbitSunParser
extends abstractFloatMeasureParser
description How many Earth years does it take for the planet to orbit the Sun?
moonsParser
extends abstractIntegerMeasureParser
description How many moons does the planet have?
boolean isMeasureRequired true
float sortIndex 1.1
akaParser
extends abstractStringMeasureParser
description What are the alternative names for the planet?
ageParser
extends abstractIntegerMeasureParser
description How old is this planet?
hasLifeParser
extends abstractBooleanMeasureParser
description Does this planet have life?
wikipediaParser
extends abstractUrlMeasureParser
description URL to the Wikipedia page.
// end measures
Extended Concepts Example
id Mars
moons 2
// Til Mars has 2 moons!
diameter 6794
surfaceGravity 4
yearsToOrbitSun 1.881
hasLife false
id Jupiter
moons 63
// The moons of Jupiter have their own Wikipedia Page
https://en.wikipedia.org/wiki/Moons_of_Jupiter moons of Jupiter
diameter 142984
surfaceGravity 25
yearsToOrbitSun 11.86
hasLife false
id Earth
moons 1
diameter 12756
surfaceGravity 10
yearsToOrbitSun 1
aka Pale Blue Dot
hasLife true
wikipedia https://en.wikipedia.org/wiki/Earth
age 4500000000
// Note: It was only during the 19th century that geologists realized Earth's age was at least many millions of years.
id Mercury
moons 0
diameter 4879
surfaceGravity 4
yearsToOrbitSun 0.241
hasLife false
id Saturn
moons 64
diameter 120536
surfaceGravity 9
yearsToOrbitSun 29.46
hasLife false
id Uranus
moons 27
diameter 51118
surfaceGravity 8
yearsToOrbitSun 84.01
hasLife false
id Venus
moons 0
diameter 12104
surfaceGravity 9
yearsToOrbitSun 0.615
hasLife false
id Neptune
moons 14
diameter 49572
surfaceGravity 11
yearsToOrbitSun 164.79
hasLife false
// end concepts
Related
May 8, 2023 — Some web apps are designed to load entire programs from a link.
But if a program contain certain characters, such as newlines, those links won't work as-is.
To create working links you have to run them through encodeURIComponent.
If you are creating blog content by hand this is annoying.
To update a program link you have to keep a copy of the program, update that, then run encodeURIComponent, then paste the result into your post.
Today's release of Scroll includes a small new addition that solves this problem. You can call them "Multline Links" or "Program Links".
Here are two examples
Here is a program link to the Scroll web app.
Here is a program link to the Scroll web app.
link https://try.scroll.pub/# program link
program
scroll
# Testing Program Links
It worked!
style color:green; font-size: 100px;
If you click that link you should see "It worked!" in big green text.
Now let's show a complex real world example. The link below contains a 28 line program pasted verbatim from the Ohayo data science studio.
See code
Discovery of the Elements
link https://ohayo.breckyunits.com?filename=test.ohayo&data=
program
doc.title Discovery of the Elements
doc.subtitle What is the growth in known elements over time?
samples.periodicTable
hidden
fill.missing Year 1000
hidden
columns.keep Element Year
hidden
rows.sortBy Year
hidden
group.by Year
hidden
rows.sortBy Year
hidden
rows.runningTotal count
hidden
vega.bar Number of Elements Found Each Year
xColumn Year
yColumn count
vega.line Cumulative Number of Elements
xColumn Year
yColumn total
vega.scatter Year of Discovery by Atomic Number
xColumn Year
yColumn AtomicNumber
tables.basic
rowDisplayLimit 200
doc.categories chemistry
If you click that link you should see a few data visualizations generated from that program.
Edit the source and the link will update accordingly. Scroll handles the encodeURIComponent.
Why not use HTML directly?
Modern browsers do their best to make URLs well-formed and you will notice that they auto encode certain characters like spaces.
But by the HTML spec newlines are not a URL code point and generally are stripped and collapsed.
Program Links in Scroll handle encoding newlines and any other special characters so you can focus on your content and not the encoding.
Improve your writing by welcoming counterarguments
April 13, 2023 — There's a tiny new symbol in Scroll today: !.
The exclamation mark stands for Counterpoint.
"Counters" aim to help writers strengthen their ideas by encouraging the integration of counterarguments throughout their essays.
You can write your own counters or invite counters from friends, LLMs or Internet commenters.
Counterpoints are easy to use: just start a line with !. For example:
Humans will eventually establish colonies on Mars.
! But we haven't colonized the Arctic, 1,000x easier
You can go as deep as you want in countering your own counters!
Humans will eventually establish colonies on Mars.
! But we haven't colonized the Arctic, 1,000x easier
- Colonizing Mars is 10,000x more valuable
The Benefits of Countering
When we have a lot of terms for a thing, it's usually a hint that it's a valuable thing. And we have a lot of terms for countering. To name a few:
- "Steel manning"
- "red teaming"
- "playing devil's advocate"
Countering is a helpful habit that helps clarify your thoughts, understand and empathize with other perspectives, fix logical blunders, hone your pitch, and improve at truth-seeking.
Counterpoints in Scroll are in a sense just a reminder to frequently use these techniques.
The Downsides of Countering
Addressing every plausible counter in your main thread can be difficult if not impossible.
It can make your writing too verbose and lose reader interest.
Counters in Scroll give you a place to record every scattered counter as it comes to you.
You can then choose which are important enough to address in your main argument and relegate the rest to the source code (for the very avid reader).
Implementation
Counterpoints do not currently appear in the compiled HTML.
Instead you only see them during write time.
For now, they are just an alternate syntax for comments.
But though they perform no new function, like traffic lines, sometimes form is function.
That being said, there are potentially interesting directions this could go in the future, and it would be interesting to hear ideas of what people would like in a v2.
Keep writing, keep thinking!
October 2, 2022 — Scroll's new blink tag lets you call attention to something important
I am really happy with the current state of Scroll and so grateful for the many people who have helped us get it to this point. That being said, I had a feeling we were missing something important.
So I invented something simple and completely novel
Introducing the blink tag. When you have something important to say and you want to interupt people's lives, use the blink tag. It's as easy as this:
blink This blinks
Advertisers have known for ages that human eyes evolved to respond fast to motion. Now, using my new invention, the blink tag, you can bring this innovation from advertising to your products and websites.
The blink tag, available now in Scroll 34.1.0
Note: please don't use this. It's a joke
The Power of Indented Heredocs: Markdown, Textile, and BBCode in one file with no escaping
by Breck Yunits
August 23, 2021 — Scroll is a new language and static site generator that is mostly written in Parsers which are both built on a new syntax called Particles.
In this demo, I extend Scroll by adding support for Markdown, Textile, and BBCode. I want to demonstrate how easy it is to compose many languages into one using Particles, which is due to what you might call the Indented or Off-side Heredoc pattern.
My implementation is still researchy—Parsers still needs a lot of work—but my main point here is to demo how simple and powerful indented heredocs are. They allow you to compose unlimited languages in one file in a clean and scalable way. You don't need escaping. I think this is a very helpful pattern you can use in your own languages and code.
Traditional Heredocs
Traditional heredocs use start and end delimiters, like these examples from Ruby and Python and Markdown:
# Heredoc in Ruby
puts <<GROCERY_LIST
Grocery list
----
1. Salad mix.
2. Strawberries
GROCERY_LIST
# Heredoc in Python
print("""
Customer: Not much of a cheese shop is it?
Shopkeeper: Finest in the district , sir.
""")
```javascript
// A heredoc/code block in Markdown
console.log(123)
```
Indented Heredocs
In contrast here is the indented/off-side heredoc pattern in Scroll.
The Demo
The code below:
markdown
### Markdown is best
textile
*No!* _textile is best_
bbCode
[u]bbCode rules![/u]
Emits this:
Markdown is best
No! textile is best
[u]bbCode rules![/u]More extensive examples are pasted below. Source is here.
Summary
A simple but largely accurate description of Particles is that it is just indented or off-side HereDocs. Or in colloquial academic speak The Off-Side Rule is all you need. Most people learn of the off-side rule via Python. Imagine if your whole language was just the off-side rule. That's basically Particles. But my code is not the important thing—the important thing is this pattern. Try it yourself—I bet you will love it.
Extended Examples
Markdown
markdown
Marked - Markdown Parser
========================
[Marked] lets you convert [Markdown] into HTML. Markdown is a simple text format whose goal is to be very easy to read and write, even when not converted to HTML. This demo page will let you type anything you like and see how it gets converted. Live. No more waiting around.
How To Use The Demo
-------------------
1. Type in stuff on the left.
2. See the live updates on the right.
That's it. Pretty simple. There's also a drop-down option in the upper right to switch between various views:
- **Preview:** A live display of the generated HTML as it would render in a browser.
- **HTML Source:** The generated HTML before your browser makes it pretty.
- **Lexer Data:** What [marked] uses internally, in case you like gory stuff like this.
- **Quick Reference:** A brief run-down of how to format things using markdown.
Why Markdown?
-------------
It's easy. It's not overly bloated, unlike HTML. Also, as the creator of [markdown] says,
> The overriding design goal for Markdown's
> formatting syntax is to make it as readable
> as possible. The idea is that a
> Markdown-formatted document should be
> publishable as-is, as plain text, without
> looking like it's been marked up with tags
> or formatting instructions.
Ready to start writing? Either start changing stuff on the left or
[clear everything](/demo/?text=) with a simple click.
[Marked]: https://github.com/markedjs/marked/
[Markdown]: http://daringfireball.net/projects/markdown/
Marked - Markdown Parser
Marked lets you convert Markdown into HTML. Markdown is a simple text format whose goal is to be very easy to read and write, even when not converted to HTML. This demo page will let you type anything you like and see how it gets converted. Live. No more waiting around.
How To Use The Demo
- Type in stuff on the left.
- See the live updates on the right.
That's it. Pretty simple. There's also a drop-down option in the upper right to switch between various views:
- Preview: A live display of the generated HTML as it would render in a browser.
- HTML Source: The generated HTML before your browser makes it pretty.
- Lexer Data: What marked uses internally, in case you like gory stuff like this.
- Quick Reference: A brief run-down of how to format things using markdown.
Why Markdown?
It's easy. It's not overly bloated, unlike HTML. Also, as the creator of markdown says,
The overriding design goal for Markdown's formatting syntax is to make it as readable as possible. The idea is that a Markdown-formatted document should be publishable as-is, as plain text, without looking like it's been marked up with tags or formatting instructions.
Ready to start writing? Either start changing stuff on the left or clear everything with a simple click.
Textile
textile
h1. level 1 heading
h2. level 2 heading
h3. level 3 heading
h4. level 4 heading
bq. this is blockquoted text
fn1. footnote 1
fn2. footnote 2
This text refernces a footnote[1]
# numbered list item 1
# numbered list item 2
* bulleted list first item
* bulleted list second item
_emphasis_
*strong*
??citation??
-deleted text-
+inserted text+
^superscript^
~subscript~
%span%
p(class). paragraph with a classname
p(#id). paragraph with an ID
p{color:red}. paragrah with a CSS style
p[fr]. paragraphe en français
p<. left aligned paragraph
p>. right aligned paragraph
p=. centered aligned paragraph
p<>. justified text paragraph
|_. head |_. table |_. row |
| a | table | row 1 |
| a | table | row 2 |
"linktext":url
!imageurl!
ABBR(Abbreviation)
level 1 heading
level 2 heading
level 3 heading
level 4 heading
this is blockquoted text
1 footnote 1
2 footnote 2
This text refernces a footnote1
- numbered list item 1
- numbered list item 2
- bulleted list first item
- bulleted list second item
emphasis
strong
citation
deleted text
inserted text
superscript
subscript
span
paragraph with a classname
paragraph with an ID
paragrah with a CSS style
paragraphe en français
left aligned paragraph
right aligned paragraph
centered aligned paragraph
justified text paragraph
| head | table | row |
|---|---|---|
| a | table | row 1 |
| a | table | row 2 |
ABBR
BBCode
bbCode
[b]bolded text[/b]
[i]italicized text[/i]
[u]underlined text[/u]
[url]https://en.wikipedia.org[/url]
[url=https://en.wikipedia.org]English Wikipedia[/url]
[img]https://upload.wikimedia.org/wikipedia/commons/7/70/Example.png[/img]
[quote]quoted text[/quote]
[code]monospaced text[/code]
[list]
[*]Entry A
[*]Entry B
[/list]
[b]bolded text[/b]
[i]italicized text[/i]
[u]underlined text[/u]
[url]https://en.wikipedia.org[/url]
[url=https://en.wikipedia.org]English Wikipedia[/url]
[img]https://upload.wikimedia.org/wikipedia/commons/7/70/Example.png[/img]
[quote]quoted text[/quote]
[code]monospaced text[/code]
[list]
[*]Entry A
[*]Entry B
[/list]